Break the Output Geometry for Large Language Model Unlearning
Abstract
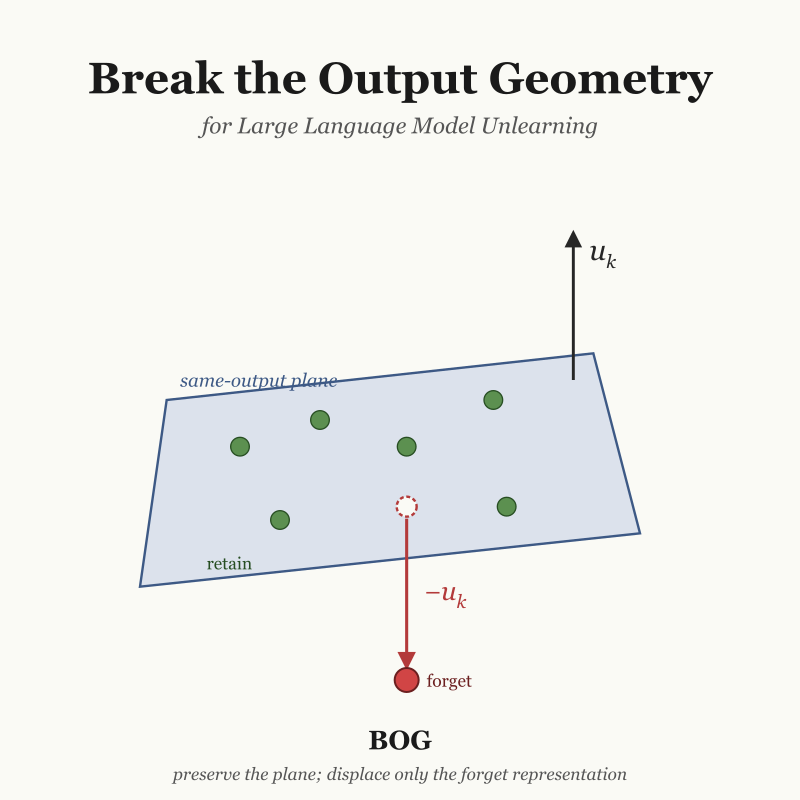
Current LLM unlearning methods face a persistent trade-off between forget effectiveness and retained-context utility. We trace this to two findings: layer-wise logit accumulation toward a target token depends more on the output token than on the input query, and hidden states producing the same token vary only along directions orthogonal to its unembedding row u_k - the same-output plane. Break the Output Geometry (BOG) preserves this plane while displacing the forget input along u_k by a margin derived from cross-output statistics, achieving a superior forget-retain trade-off on TOFU.
Publication
ICML 2026 Workshop on Memory in Foundation Models (MemFM) 2026
Links